

When we talk about a JavaScript engine what we’re usually referring to is the compiler; a program that takes human-readable source code (in our case JavaScript) and from it generates machine-readable instructions for your computer. If you haven’t considered what happens to your code when it runs this can all sound rather magical and clever but it’s essentially a translation exercise. Making that code run fast is what’s clever.
How a simple compiler works
JavaScript is considered a high level language, meaning it is human readable and has a high degree of flexibility. The job of the compiler is to turn that high level code into native computer instructions.
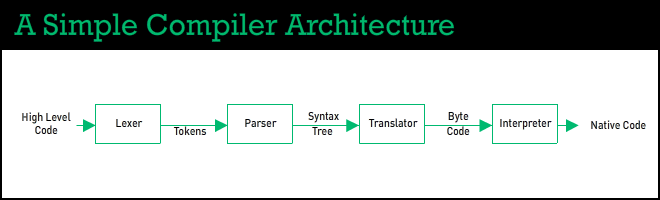
A simple compiler might have a four-step process: a lexer, a parser, a translator and an interpreter.
- The lexer, or lexical analyser (or scanner, or tokeniser) scans your source code and turns it into atomic units called tokens. This is most commonly achieved by pattern matching using regular expressions.
- The tokenised code is then passed through a parser to identify and encode its structure and scope into what’s called a syntax tree.
- This graph-like structure is then passed through a translator to be turned into bytecode. The simplest implementation of which would be a huge switch statement mapping tokens to their bytecode equivalent.
- The bytecode is then passed to a bytecode interpreter to be turned into native code and rendered.
This is a classic compiler design and it’s been around for many years. The requirements of the desktop are very different however from those of the browser. This classic architecture is deficient in a number of ways. The innovative way in which these issues were resolved is the story of the race for speed in the browser.
Fast, Slim, Correct
The JavaScript language is very flexible and quite tolerant of obtuse programmatic constructs. So how do you write a compiler for a late-binding, loosely-typed, dynamic language? Before you make it fast you must first make it accurate, or as Brendan Eich puts it,
“Fast, Slim, Correct. Pick any two, so long as one is ‘Correct’”
An innovative way to test the correctness of a compiler is to “fuzz” it. Mozilla’s Jesse Ruderman created jsfunfuzz for exactly this purpose. Brendan calls it a “JavaScript travesty generator” because it’s purpose is to create weird but valid syntactic JavaScript constructs that can then be fed to a compiler to see if it copes. This kind of tool has been incredibly helpful in identifying compiler bugs and edge cases.
JIT compilers
The principle problem with the classic architecture is that runtime bytecode interpretation is slow. The performance can be improved with the addition of a compilation step to convert the bytecode into machine code. Unfortunately waiting several minutes for a web page to fully compile isn’t going to make your browser very popular.
The solution to this is “lazy compilation” by a JIT, or Just In Time compiler. As the name would suggest, it compiles parts of your code into machine code, just in time for you to need it. JIT compilers come in a variety of categories, each with their own strategies for optimisation. Some like say a Regular Expression compiler are dedicated to optimising a single task; whereas others may optimise common operations such as loops or functions. A modern JavaScript engine will employ several of these compilers, all working together to improve the performance of your code.
JavaScript JIT compilers
The first JavaScript JIT compiler was Mozilla’s TraceMonkey. This was a “tracing JIT” so-called because it traces a path through your code looking for commonly executed code loops. These “hot loops” are then compiled into machine code. With this optimisation alone Mozilla were able to achieve performance gains of 20% to 40% over their previous engine.
Shortly after TraceMonkey launched Google debuted its Chrome browser along with it’s new V8 JavaScript engine. V8 had been designed specifically to execute at speed. A key design decision was to skip bytecode generation entirely and instead have the translator emit native code. Within a year of launch the V8 team had implemented register allocation, improved inline caching and rewritten their regex engine to be ten times faster. This increased the overall speed of their JavaScript execution by 150%. The race for speed was on!
More recently browser vendors have introduced optimising compilers with an additional step. After the Directed Flow Graph (DFG) or syntax tree has been generated the compiler can use this knowledge to perform further optimisations prior to the generation of machine code. Mozilla’s IonMonkey and Google’s Crankshaft are examples of these DFG compilers.
The ambitious objective of all this ingenuity is to run JavaScript code as fast as native C code. A goal that even a few years ago seemed laughable but has been edging closer and closer every since. In part 3 we’ll look at some of the strategies compiler designers are using to produce even faster JavaScript.